13-Feb-2015の続き(最近、続き物が多いな)。
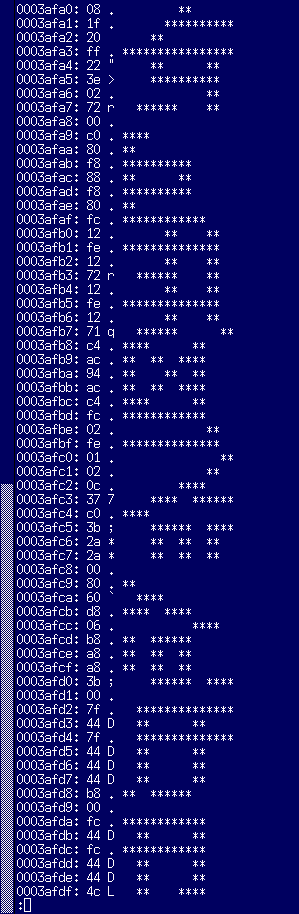
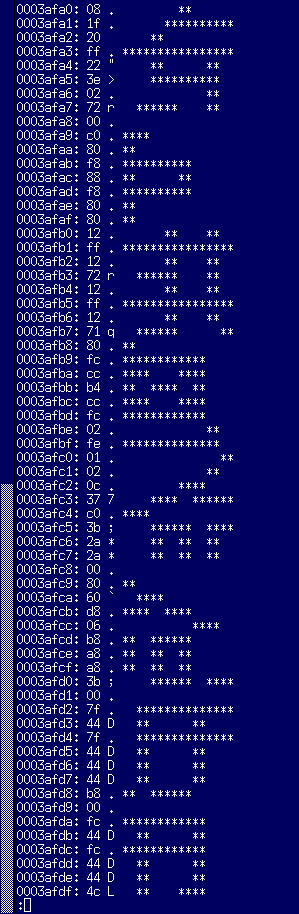
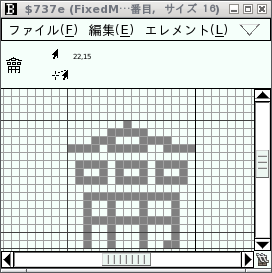
JIS第二水準の存在チェックは、龠(83区94点)の左上8×8のチェックサムで決定されると書いたので、ちょっとこの部分を詳細に見てみることにしました。左からMSX-Write II, FS-A1ST, HBI-J1の順に、一つ前の龜(83区93点)と併せて表示させています。
この三つの漢字ROMにおいて、龜は全て異なっているのに対し、龠は全て同じです。龠の左上8×8のチェックサムは全て0x01 + 0x02 + 0x0c + 0x37 + 0xc0 + 0x3b + 0x2a + 0x2a = 0x195。最初見たときは自分の目を疑いましたよ。
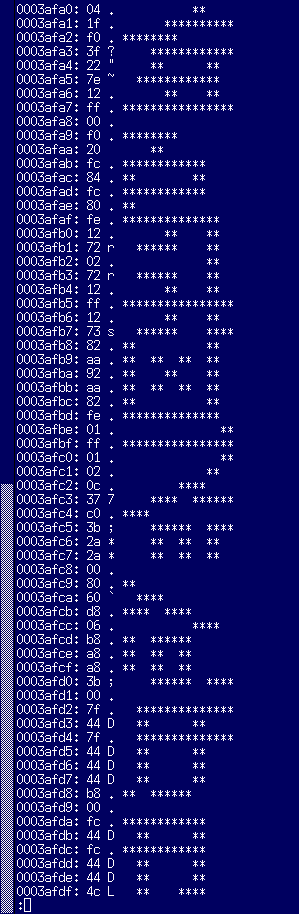
jiskan16を使っているHBI-J1との比較のため、X(OpenBSD-5.7/amd64)のjiskan16.pcf.gzの龠の左上8×8も見てみることにします。
左上8×8のチェックサムは0x01 + 0x07 + 0x1c + 0xf7 + 0x00 + 0x7b + 0x4a + 0x7b = 0x25b。これで第二水準の存在チェックを通すことはできないので、このグリフだけ他から引っ張ってきたと考えるのが妥当でしょうか。三洋のMSX2+もjiskan16/東芝系とは異なる流派の漢字ROMを使っていると聞きますので、こちらも見てみたいところではありますが…実機無しでやるというのも問題でしょうし。
第一水準の存在チェックで使用する\(1区32点)と同様に、龠についても差し替えることで第二水準対応を行えることは間違いなさそうですが、龠を構成する32byteのデータを引用して良いものかどうかというのはかなり悩むところであります。\を引っ張ってきている時点で何を言っているんだという話にはなりますが(ただしこちらは仕様に「左上8×8が0x00, 0x40, 0x20, 0x10, 0x08, 0x04, 0x02, 0x01となる」という明確な定義がある)。
とりあえず個人的な実験を目的として拝借する分には…構いませんかね?58.35kg(05:55)