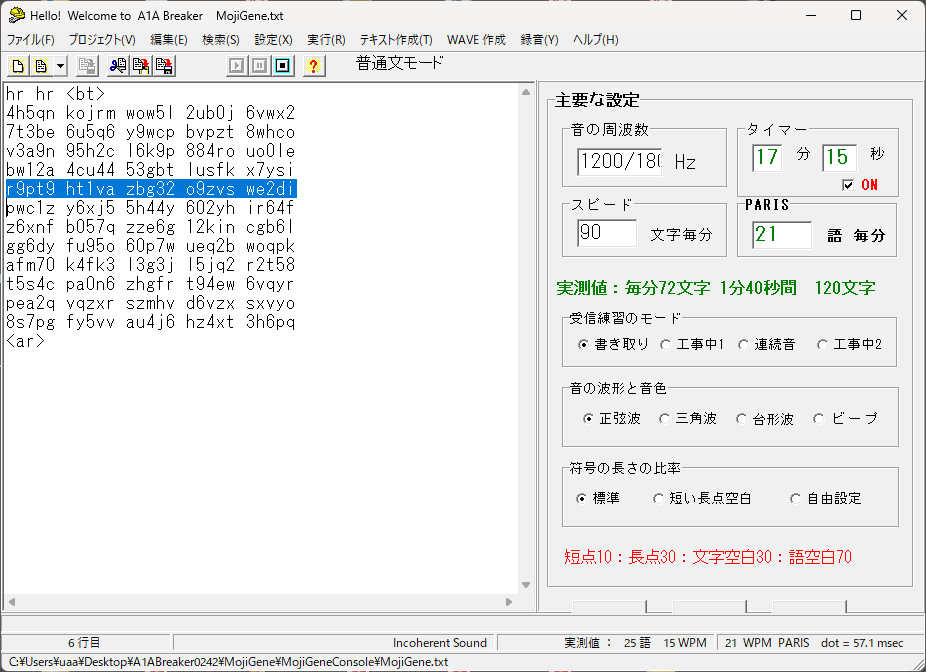
A1A Breakerから呼び出す文字列生成用の外部プログラム(MojiGene\MojiGeneConsole\MojiGene.exe)、使用する文字を任意に設定できるようにしたりUTF-8入出力とShift-JIS出力対応を入れたりしたものをGitHubに上げてしまいました。
UCS-4→Shift-JIS変換を行う必要があるのと、PC-UNIX以外でUTF-8ロケールの処理を行えるかは不明なため、UTF-8のエンコード/デコードを自前で行っています(脆弱性を招く可能性があり、この手の処理は実績のあるライブラリを使用することが推奨されていることは知っています)。処理を行うコードがMITライセンスになっているのは、FUJIMI-IM/sj3のUTF-8対応版sj3(tty client)向けに書いたコードをちょっといじって載せたのが理由です。PC-UNIX上で使うことしか考えないのであれば<wchar.h>を使ってもう少しシンプルに書けるのですが、gcc/clangだけでなくOpenWatcomやLCC-Winでもビルドできるのでこれで良しとします。
今後機能を追加するとしたら、設定ファイル(MojiGene.ini)の切り替え機能くらいでしょうか。UTF-8ロケール以外のコマンドライン(Windows PowerShell等)で使用した場合は、一部のオプションでUS-ASCIIの範囲外の文字を正しく扱えません。これはMojiGene.iniに記述すれば回避できるという理由により、対応しないことにします。
仕事場の昼休みでちょっと受信練習ができたら良いなということでAndroid端末にMorseLearnProを入れ、人のいないときに練習しています。このソフトウェアでは速度の設定をCPM(character per minute)で設定するようになっているので90CPMにして聴いているのですが、妙に速いなーと思ったのでAudacity(PCMエディタ)を使って調べてみました。
簡単に測ってみると、50CPM時における長点の長さが250ms。PARIS 20WPM(100CPM)における短点は60msなので、その半分の速度である10WPM(50CPM)なら120ms→長点だったら3倍して360ms。MorseLearnProは1.44倍速い、ということになるのでしょうか。念のため問い合わせもしておりまして、25CPM時に短点240msとしているという回答を得ています…つまり50CPM時は短点120msになるはず(しかもPARIS WPM準拠)ということで、「妙に速い」という認識は間違いではないようです。
12500÷(MorseLearnProのCPM×3)が短点の長さ(ms)という公式が分かったのは良いとして、もう一つの疑問があります。トーン周波数の設定が600Hzの状態で、鳴っている周波数をWaveSpectraで調べてみたら652Hz。サンプリング周波数44100Hzで作ったデータを、48000Hzの設定で鳴らしている可能性があります(この件については報告済みです)。とはいえ、48000÷44100=1.088倍の再生速度の違いが送信速度の違いにどう結びついているのかが分かりません。単純な算数の問題なのか、あるいは別々の問題が絡んでそう見えるのか…
とりあえず、なかなか受信した文字が書き取れない(100文字のうち10文字は落としています)原因が分かったことと、これはこれで取れない文字は即座に捨てて次の文字に食らい付く練習にはなっているので、有益なのだと思います多分。55.5kg(21:50)
04-Jun-2025補足:MorseLearnPro他、FKT氏作成のモールス符号学習系ソフトウェアのアップデートが行われています。100CPMの設定で短点が60ms(PARIS 20WPM)になっていることと、600Hz設定で600Hzのトーンが出ていることをMorseLearnProで確認しました。CPMの上限が100→150に引き上げられているので、今まで90CPMに設定していたなら130CPMの設定で同様な練習が可能に…ってそんな速度で練習してたのか。