電気通信術(欧文)の練習、PARIS 24WPMの暗語で300文字のうち10文字落とすかどうかくらいの領域までどうにか来ることができました。とはいえ調子次第では20文字以上落とすこともあり、未だ安定しません。普通文の練習をそろそろ始めないとなーと考えている際に、3.1.3普通語への対応(plus TK2S)にある、暗語は取れても普通文は取れないことについて調べてみました(リンク先に答えは書かれていますけどね)。
欧文モールス符号、文字の出現率に応じて最適化されていることはよく知られている話です。では文字の出現率とは実際どんな数字なのか…genspark.aiに尋ねたところLetter Frequencies in Englishを紹介されたので、これを使います。この統計が何をソースにしているのかについては、とりあえず一旦脇に置きます。
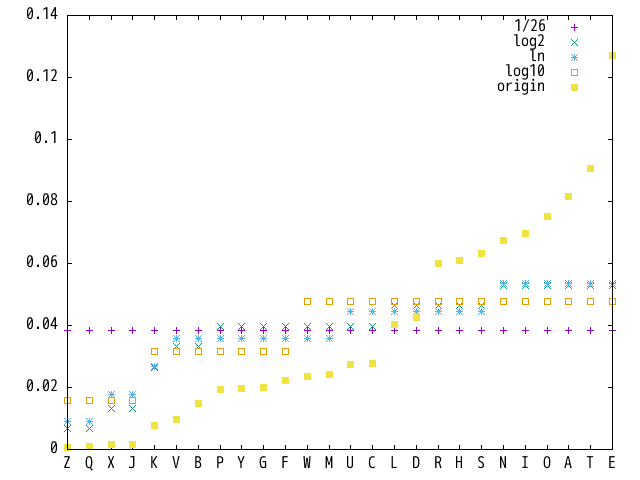
頻繁に出てくるe(0.12702)、滅多に出てこないz(0.00074)、171.65倍の開きがあります。MojiGeneが乱文を生成する際に使用する文字セット(主)(CharGroup0)の指定は、同じ文字を書けば書くほどその文字が出やすくなる作りになっているので、出現率の高い文字を数多く記述すれば実現できそうですが…現時点の作りでは、設定ファイルの一行の上限は改行文字とヌル文字を含めて256文字です。なので、eを172個列挙するのは流石に無理があります。また、ここまで極端にeやt(0.09056)が突出していると、他の文字の練習はおろそかにならないのかという疑問もあります。
出現率をそのまま使ってしまうとあまりにも幅が広いため、列挙する文字の数をこんな感じで求めてみることにしました。ばらけ具合(?)はlogの底で調整しますが、log2, ln, log10を比べるに…とりあえずlnで良さそうな気がします。
対数で処理しているため実際の出現率より穏やかになっているとはいえ、出現率一定(1/26)から少し偏らせてみるとどうなるかという実験としてはこれで十分でしょう。
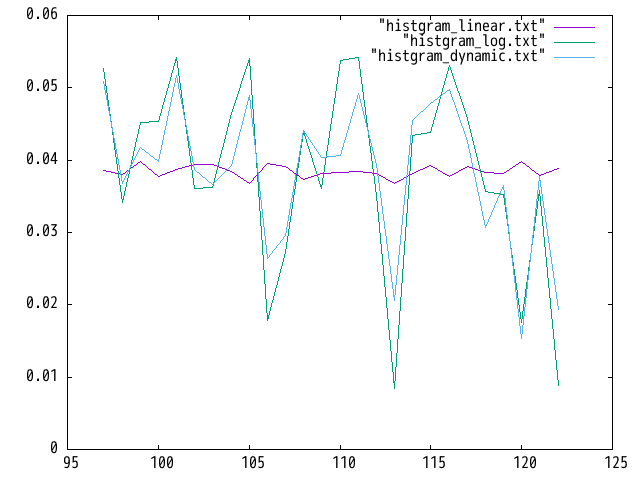
という訳で、"CharGroup0 = eeeeeettttttaaaaaaooooooiiiiiinnnnnnssssshhhhhrrrrrdddddlllllcccccuuuuummmmwwwwffffggggyyyyppppbbbbvvvvkkkjjxxqz"を指定して作成した暗語をa1a_genで鳴らしてみると…同じPARIS 24WPMでも速いです。出現率一定だと100cpmくらいなのに対し、こちらは110cpm。流石に取れなくなります。実際の出現率に合わせると、文字通り120cpmまで跳ね上がるのかもしれません。
結論として、符号自体の速度は同じであっても「単位時間当たりの符号の数」が普通文では増すため、通信速度が上がります。短い符号が増えればその分速くなるのは当たり前だろ?という話ではあるのですが…だとしても、普通文が速く感じるのは何故なのかと気になっていましたから。57.9kg(23:35)
18-Jan-2026補足:出現率を対数で処理しない場合のCharGroup0を作ってみました。MojiGeneに手を入れてこれを扱えるようにし(現時点ではdevブランチのみです)、a1a_genで鳴らすと130cpm近辺まで跳ね上がります。流石にこれで練習するのは厳しそうなので、まずは対数(ln)で処理したものを使うことにします。