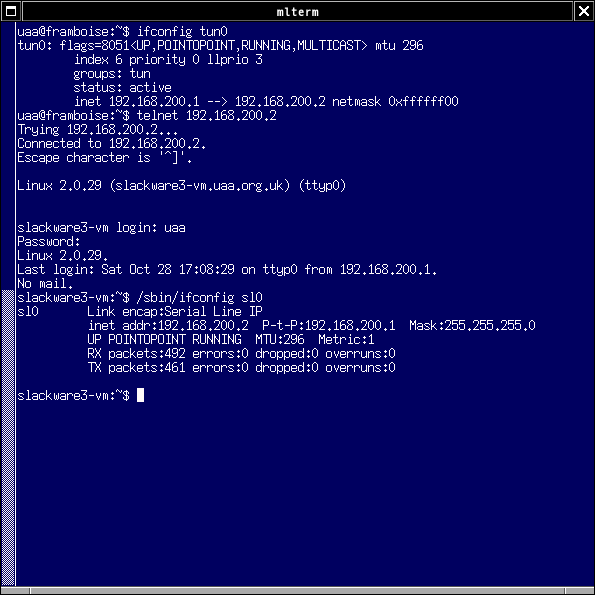
ディスクイメージからファイルを取り出すのは難しくないです…大文字のファイル名を使うのはUNIX的にどうなのという気はしますが、エミュレータ上で大文字小文字の違いに悩まされるのも嫌なのでmount_msdos -l(デフォルト)でマウントしています。※mount_msdos -sもしくは-9の場合、ファイル名は小文字になります。
- ディスクイメージの型式変換
- qemu-img convert pcdos2000-vm.vmdk pcdos2000-vm.raw
- ディスクイメージのマウント
- vnconfig vnd0 pcdos2000-vm.raw; mount_msdos -l /dev/vnd0i /mnt
- ファイル取り出し
- mkdir ~/dos; cp -r /mnt ~/dos/c
- ディスクイメージのマウント解除
- umount /mnt; vnconfig -u vnd0
あとはDOSBoxの利用と似たような手順になると思っていました。CONFIG.SYS内でCOUNTRY=による設定が行えない問題を回避するためのCHEJ 6.10と、デバイスドライバの組み込みに使うadddev/deldevは、とりあえず~/dos/dに入れておきます。
DOSをインストールした直後ではなく少し手が入っている状態のCONFIG.SYSですが、ここから最低限必要そうなものを組み込んでDOSBox上での動作を確認していきます。
- mount c ~/dos/c
- mount d ~/dos/d
- c:
- d:\adddev +c:\dos\$font.sys
- d:\chej jp ※ここで日本語モードにしないと次が動きません
この後にd:\adddev +c:\dos\$disp.sysとすれば日本語表示はできる…はずなのですが、こうなりました。$disp.sysのオプションを<なし>, /hs=off, /hs=on, /hs=lcどれを試しても変わりません。
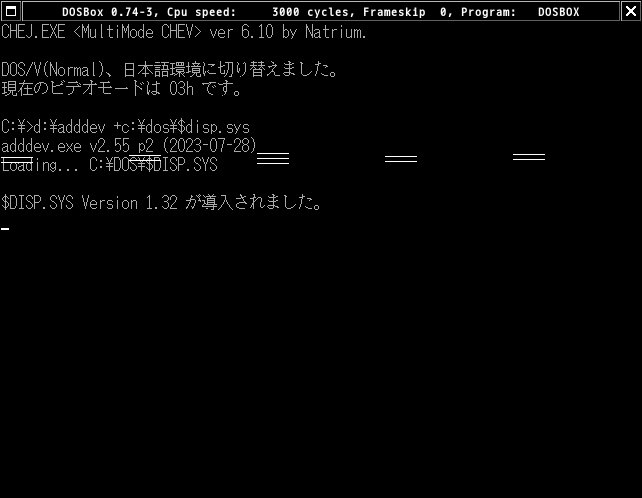
VectorのDOS/V V-TEXT用ユーティリティにあるディスプレイドライバを片っ端から試してみましたが、何を使ってもこんな感じです。
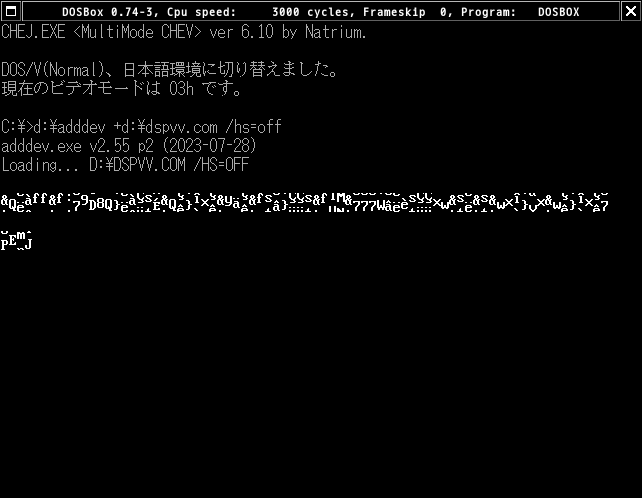
他に、以下のようなことを試しているのですが…
- Web Archiveからしか入手できなくなったような感じのDISPVも動作せず
- Debian-12.1上のDOSBox-0.74-3でも同様に動作せず
- VMware Player上のPC-DOS 2000上でHIMEM.SYSのみ組み込むような内容のCONFIG.SYSを作成し、adddev.exeやchej.exeを使って$disp.sysや$font.sysを組み込んでみたがこれは問題無し
CONFIG.SYSではなくadddev.exeでドライバを登録することによる問題というよりは、DOSBox側の問題のようです。どうやらdosbox-0.72-int10con.patchというパッチが存在するようなので、おそらくこれが適用されていないDOSBoxではどう頑張ってもDOS/V化できないということになるのでしょう。DOSBox-Xではエミュレータ自体がDOS/Vの機能を持っているらしいという話があるので、そちらを待つ方が良いのかもしれません。55.2kg(22:15)